
Introduction to Machine Learning
Published:
Introduction to Machine Learning
If you are a newbie, want to know where to start studying and why you need Machine Learning and why it is gaining more and more popularity lately, you got into the right place!

“When you’re fundraising, it’s AI. When you’re hiring, it’s ML. When you’re implementing, it’s just a Regression.” — everyone on Twitter ever
No, Machine Learning isn’t just glorified statistics. Let’s see what it actually means.
In general, Machine Learning is incredibly useful for difficult tasks when we have incomplete information or information that’s too complex to be coded by hand. So, lazy people made it popular and we call them data scientists.
Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.
Yes, go through the above paragraph again.
In layman terms, machine learning is the science of getting computers to realize a task without being explicitly programmed.
Okay, Machine Learning is interesting…!!! But why not Traditional Programming?
Traditional Programming vs Machine Learning
Traditional Programming
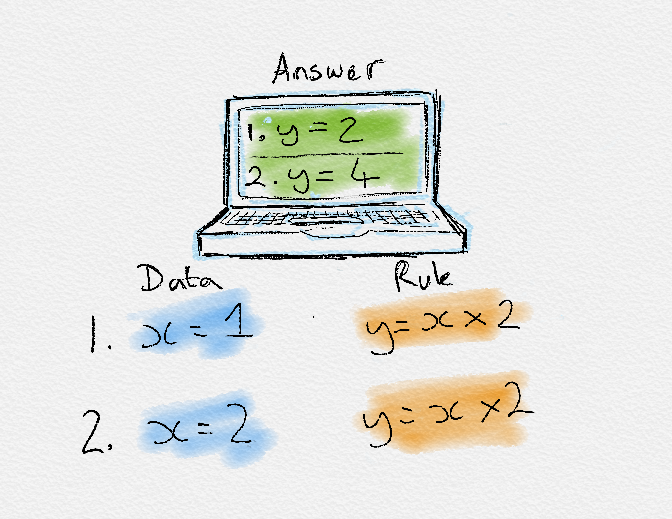
In traditional programming, we design an algorithm which is a set of instructions or rules, to which we give input and get the desired output. This is a rule-based approach.
Machine Learning
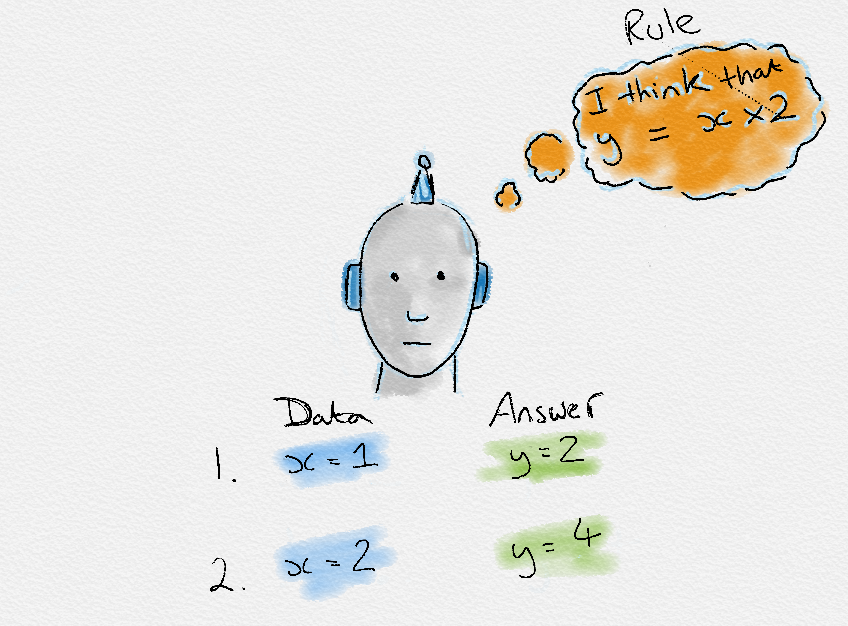
In Machine Learning, we give both input and its corresponding output, and the system learns the trend of data by applying some maths, so it can predict results for future unseen inputs.
Wait, what on the earth brought math here? It’s simple, anything in the world could be described with math.
So basically, Machine learning is learning based on experience. As an example, it is like a person who learns to play chess through observation as others play.
But, how is Machine Learning different from Deep Learning?
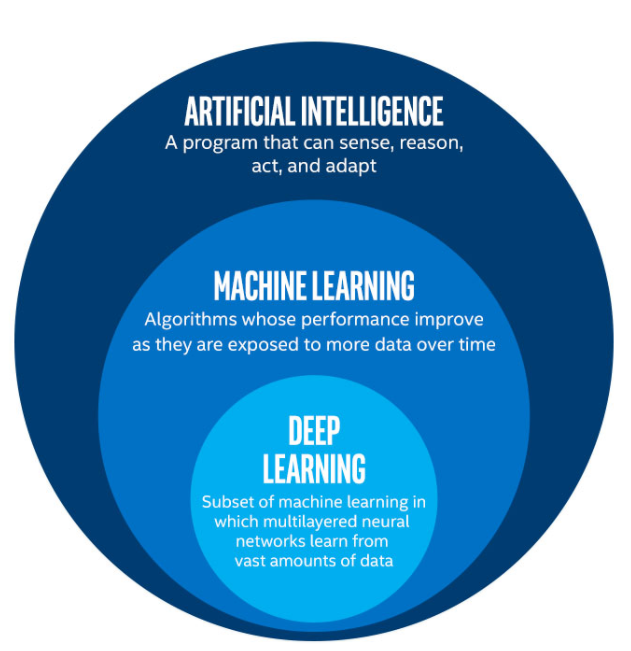
Deep learning is a sub-field of machine learning in Artificial intelligence (A.I.) that deals with algorithms inspired from the biological structure and functioning of a brain to aid machines with intelligence.
Applications of Deep Learning:
- Self-driving cars
- Deep Learning in Healthcare
- Voice Search & Voice-Activated Assistants
- Automatically Adding Sounds To Silent Movies
- Automatic Machine Translation
- Automatic Text Generation
- Automatic Handwriting Generation
- Image Recognition
- Automatic Image Caption Generation
- Automatic Colorization
- Advertising
- Predicting Earthquakes
- Neural Networks for Brain Cancer Detection
- Neural Networks in Finance
- Energy Market Price Forecasting
These applications may give you a clearer idea of the current and future capabilities of deep learning technologies which are intended to rule the world. So, this is why it is gaining more and more popularity lately and you’re hearing a lot, at least trolling it in memes.
Here, we will stick to the basics of Machine Learning.
Terminology
We will get this terminology off the chest before a marathon.
- Dataset
- A set of data examples, that contain features (inputs) and corresponding solutions (outputs).
- Features
- Important pieces of data that help us understand a problem. These are fed into a Machine Learning algorithm(model) to help it learn.
- Model
- The representation of a phenomenon that a Machine Learning algorithm has learnt. It learns this from the data during training. The learnt model is used to predict new outcomes according to the given input data.
- Generalisation
- The ability of a model to learn a general formula that generalises the underlying patterns or mappings from input data to output data. Generalised models can predict new unseen input data pretty well.
- Overfitting
- The model is said to be overfitting, if it stops learning and starts memorising things. Overfitted models are very bad at predicting new unseen input data.
Don’t worry if it’s getting a bit harsh. We will discuss it later in detail.
Okay, Let’s go Ahead.
Steps of Machine Learning
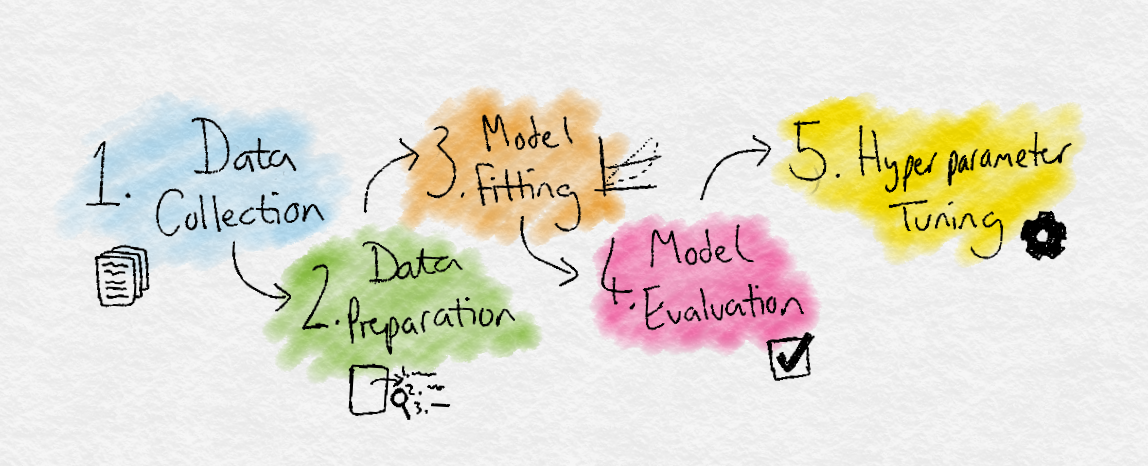
- Data collection
- Defining the problem and assembling a dataset
- Data preparation
- Preparing your data accordingly
- Choose model
- Choose an appropriate algorithm
- Train model
- Developing a model to learn from input data
- Evaluate model
- Choosing a measure of success
- Parameter tuning
- Adjusting parameters of model for better outcomes
- Predict
- Predict outcome based on new unseen input data.
These steps are just an abstraction of the workflow. These may vary accordingly to the problem, situation, programmer, etc.
Types of Machine Learning
The two main categories of machine learning techniques are supervised learning and unsupervised learning. We will discuss it in brief now.
Supervised Learning
Supervised learning is when a computer is presented with examples of inputs and their desired outputs. The goal of the computer is to learn a general formula which maps inputs to outputs. This can be basically further broken down into Regression, Classification, etc.
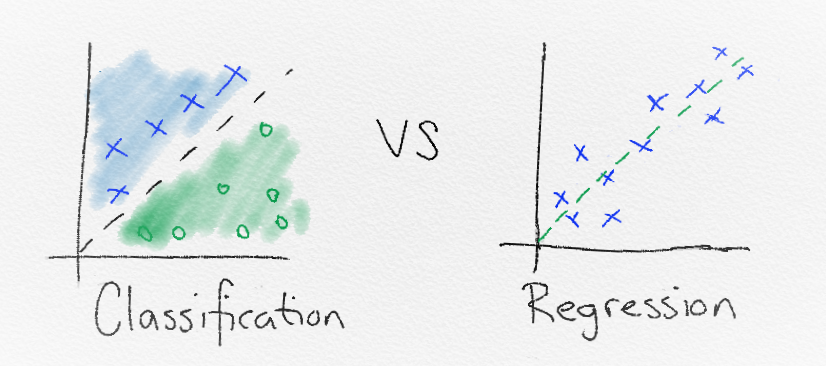
Regression
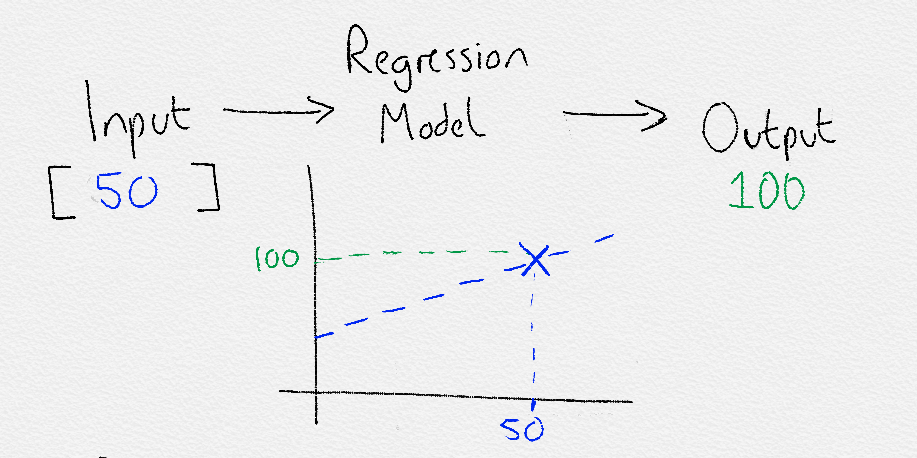
Regression is the algorithm which learns the dependency/relation (i.e., a $function: y=f(x)$) between each known $x$(input) and $y$(output), such that later we can use it to predict $y$(output) for an unknown sample of $x$(input). If the function is graphically represented as a straight line (i.e., in $2D, y=mx+c$), then it is Linear Regression.
But what if your outcome variable y is “categorical”? That’s where classification comes in!
Wait, but what is a categorical variable?
Categorical variables are just variables that can be only fall within in a single category like:
- Is this image “Cat” or “Dog”?
- Is it “Good” or “Bad”?
- Is he “Fat” or “Thin”?
Classification
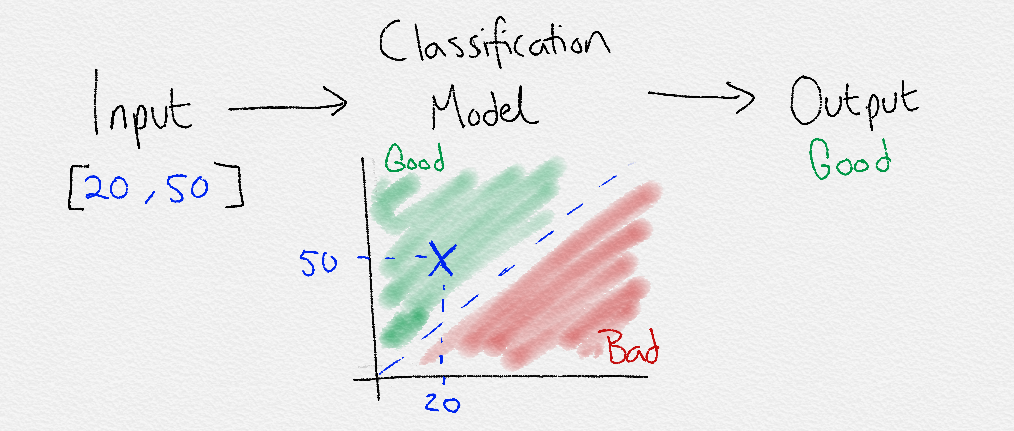
Classification is used to find the rules that explain how to separate the different data points (usually) with a line. The line drawn between classes is known as the decision boundary. The entire area that is chosen to define a class is known as the decision surface. The decision surface defines that if a data point falls within its boundaries, it will be assigned a certain class or label.
Unsupervised Learning
In unsupervised learning, only input data is provided in the examples. There are no labelled example outputs to aim for. But it may be surprising to know that it is still possible to find many interesting and complex patterns hidden within data without any labels.
Unsupervised learning is mostly used for clustering.
Clustering
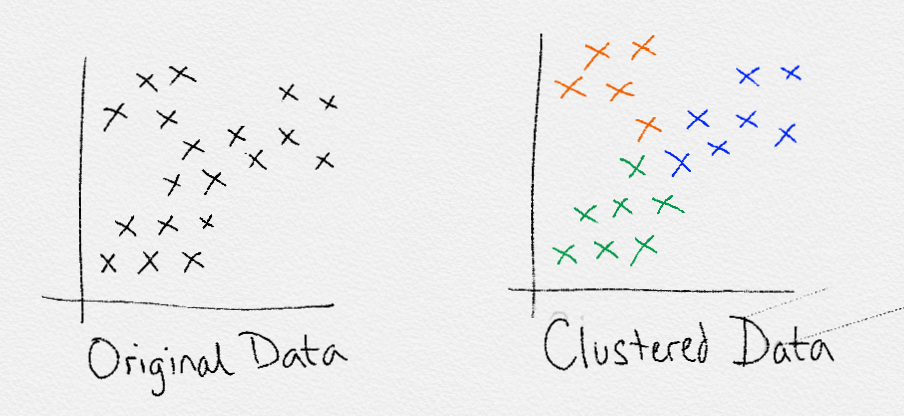
Clustering is the act of creating groups with differing characteristics. Clustering attempts to find various subgroups within a dataset. Note that this algorithm uses only input training data $(x)$ but not including output training data $(x,y)$.
Reinforcement Learning
This is a special type of machine learning which focuses on learning through penalty and rewards. This is mostly implemented in Video Games and Robotics. We will look into this later.
Here it comes - Python

“Talk is cheap. Show me the code.” ― Linus Torvalds
If your aim is growing into a successful coder, you need to know a lot of things. But, for Machine Learning & Data Science, it is pretty enough to master at least one coding language and use it confidently. So, calm down, you don’t have to be a programming genius.
Why Starting With Python ?
My opinion — Python is a perfect choice for a beginner to make your focus on in order to jump into the field of machine learning and data science. It is a minimalistic and intuitive language with a full-featured library line (also called frameworks) which significantly reduces the time required to get your first results.
You can also, by the way, consider the R language.
But…

“We don’t do that there” — Black Panther, Movie (2018)
We will try to code Machine Learning in Python in the next post.
Meanwhile, have a grasp of Python, Numpy, Pandas, Matplotlib.
Stand by. Stay Tuned. More to follow.